Hive provides SQL-like query language on HDFS(Hadoop Distributed File System) | ||
 1,067 1,067  0 0  0 0 | ||
| Hive defines a simple SQL-like query language, called QL, that enables users familiar with SQL to query the data. At the same time, this language also allows programmers who are familiar with the MapReduce framework to be able to plug in their custom mappers and reducers to perform more sophisticated analysis that may not be supported by the built-in capabilities of the language. QL can also be extended with custom scalar functions (UDF's), aggregations (UDAF's), and table functions (UDTF's).
Hive Query Language provides following features Basic SQL
Extensibility
See below example of Hive query language. Amaging thing is Hiveis compatible with standard SQL. SELECT pageid, COUNT(DISTINCT userid) It is almost the same as the usual RDB SQL. This is really great feature of Hive so programmers having experiences in RDB can implement software easily. Hive does not mandate read or written data be in the "Hive format"---there is no such thing. Hive works equally well on Thrift, control delimited, or your specialized data formats. Please see File Format and SerDe in the Developer Guide for details. Hive is not designed for OLTP workloads and does not offer real-time queries or row-level updates. It is best used for batch jobs over large sets of append-only data (like web logs). What Hive values most are scalability (scale out with more machines added dynamically to the Hadoop cluster), extensibility (with MapReduce framework and UDF/UDAF/UDTF), fault-tolerance, and loose-coupling with its input formats.
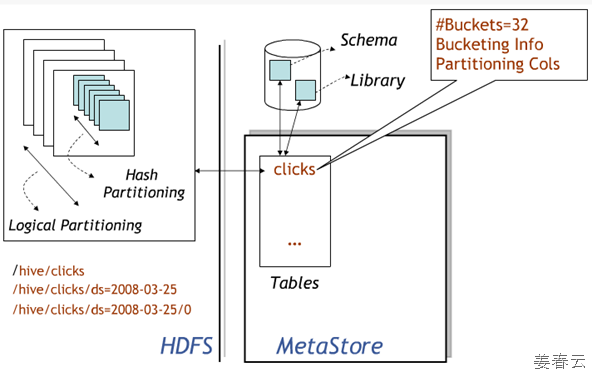
Following is Data Model for Hive.
References https://cwiki.apache.org/confluence/display/Hive/Home Hive ApacheCon 2008, New Oreleans, LA (Ashish Thusoo, Facebook) Tags: AWS Amazon Blob Chun Computers & Internet HBase Hadoop Mascot Java NoSQL TRANSFORM TaskTracker UDAF UDF UDTF | ||
| | ||
|

 3184
3184