HDFS(Hadoop Distributed File System) is designed to run on commodity hardware – Low cost hardware | ||
 1,064 1,064  0 0  0 0 | ||
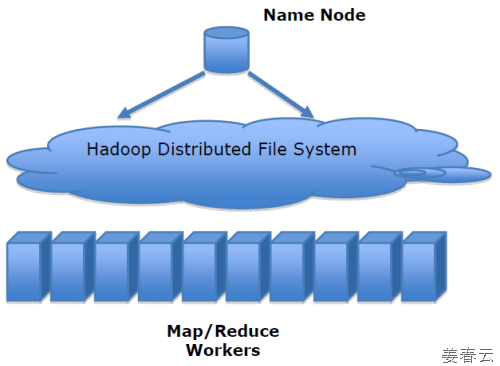
| The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant.
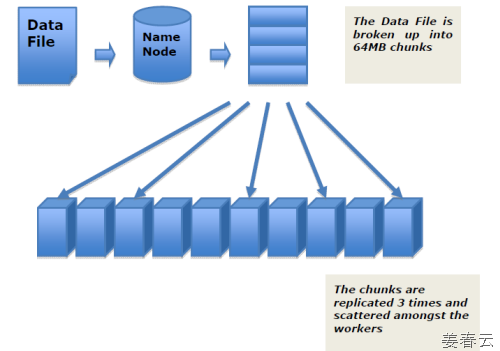
HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject. The project URL is http://hadoop.apache.org/hdfs/.
The goal of HDFS
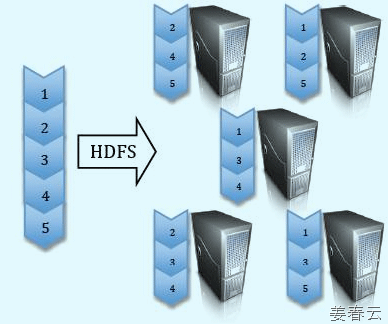
Data Replication HDFS is designed to reliably store very large files across machines in a large cluster.
MapReduce Software Framework Offers clean abstraction between data analysis tasks and the underlying systems challenges involved in ensuring reliable large-scale computation.
- Processes large jobs in parallel across many nodes and combines results.
References http://hadoop.apache.org/common/docs/current/hdfs_design.html http://www.cloudera.com/what-is-hadoop/hadoop-overview/ http://www.infoq.com/articles/data-mine-cloud-hadoop Tags: Blob Computers & Internet HBase Hadoop Mascot Java NoSQL TaskTracker | ||
| | ||
|

 3184
3184